ťĘÜŚŹĖPDFÁČąŚŅÖšľöŤÄÉÁāĻ>>

ÔľąšłÄԾȌĚáŚÄľÔľöŤģĺšłÄÁĽĄśēįśćģšłļX1ÔľĆX2ÔľĆ...ÔľĆXnԾƌĻ≥ŚĚáśēįÁöĄŤģ°Áģó
ÔľąšļĆԾȚł≠šĹćśēį‚ÄĒ‚ÄĒŚÖąśéíŚļŹŚÜćśČĺšł≠ťóīšĹćÁĹģ
„ÄÄ„ÄÄŤģĺšłÄÁĽĄśēįśćģšłļX1ÔľĆX2ԾƂĶԾĆXnԾƜĆČšĽéŚįŹŚąįŚ§ßť°ļŚļŹšłļXÔľą1ÔľČÔľĆXÔľą2ÔľČԾƂĶԾĆXÔľąnÔľČԾƌąôšł≠šĹćśēįšłļÔľö
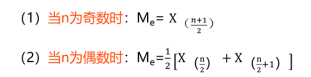
ÔľąšłČԾȚľóśēį
šľóśēįśėĮśĆášłÄÁĽĄśēįśćģšł≠ŚáļÁéįś¨°śēįÔľąťĘĎśēįԾȜúÄŚ§öÁöĄŚŹėťáŹŚÄľ„Äā
ÔľąšłÄԾȜĖĻŚ∑ģ
1.ŚĮĻšļéśÄĽšĹďśēįśćģÔľąNšłļśÄĽšĹďŤßĄś®°ÔľČ


3.ÁĽďŤģļ
Ôľą1ԾȜ†áŚáÜŚ∑ģÁöĄŚ§ßŚįŹšłćšĽÖšłéśēįśćģÁöĄśĶčŚļ¶ŚćēšĹćśúČŚÖ≥ԾƚĻüšłéŤßāśĶčŚÄľÁöĄŚĚáŚÄľŚ§ßŚįŹśúČŚÖ≥ԾƚłćŤÉĹÁõīśé•ÁĒ®ś†áŚáÜŚ∑ģśĮĒŤĺÉšłćŚźĆŚŹėťáŹÁöĄÁ¶Ľśē£Á®čŚļ¶„Äā
Ôľą2ÔľČÁ¶Ľśē£Á≥Ľśēįś∂ąťô§šļÜśĶčŚļ¶ŚćēšĹćŚíĆŤßāśĶčŚÄľśįīŚĻ≥šłćŚźĆÁöĄŚĹĪŚďćԾƌŹĮšĽ•Áõīśé•ÁĒ®śĚ•śĮĒŤĺÉŚŹėťáŹÁöĄÁ¶Ľśē£Á®čŚļ¶„Äā
ÔľąšłÄԾȌĀŹśÄĀÁ≥Ľśēį
1.Ś¶āśěúŚĀŹśÄĀÁ≥ĽśēįÁ≠Čšļé0ԾƍĮīśėéśēįśćģÁöĄŚąÜŚłÉśėĮŚĮĻÁßįÁöĄÔľõ
2.Ś¶āśěúŚĀŹśÄĀÁ≥Ľśēįšłļś≠£ŚÄľÔľĆŤĮīśė錹܌łÉšłļŚŹ≥ŚĀŹÁöĄ„Äā
Ôľą1ԾȌŹĖŚÄľŚú®0ŚíĆ0.5šĻčťóīŤĮīśėéŤĹĽŚļ¶ŚŹ≥ŚĀŹÔľõ
Ôľą2ԾȌŹĖŚÄľŚú®0.5ŚíĆ1šĻčťóīŤĮīśėéšł≠Śļ¶ŚŹ≥ŚĀŹÔľõ
Ôľą3ԾȌŹĖŚÄľŚ§ßšļé1ŤĮīśėéšł•ťá挏≥ŚĀŹ„Äā
3.Ś¶āśěúŚĀŹśÄĀÁ≥ĽśēįšłļŤīüŚÄľÔľĆŤĮīśė錹܌łÉšłļŚ∑¶ŚĀŹ„Äā
Ôľą1ԾȌŹĖŚÄľŚú®0ŚíĆ-0.5šĻčťóīŤĮīśėéŤĹĽŚļ¶Ś∑¶ŚĀŹÔľõ
Ôľą2ԾȌŹĖŚÄľŚú®-0.5ŚíĆ-1šĻčťóīŤĮīśėéšł≠Śļ¶Ś∑¶ŚĀŹÔľõ
Ôľą3ԾȌŹĖŚÄľŚįŹšļé-1ŤĮīśėéšł•ťáćŚ∑¶ŚĀŹ„Äā
4.ŚĀŹśÄĀÁ≥ĽśēįÁöĄÁĽĚŚĮĻŚÄľŤ∂䌧ßԾƍĮīśėéśēįśćģŚąÜŚłÉÁöĄŚĀŹśĖúÁ®čŚļ¶Ť∂䌧߄Äā
ÔľąšļĆԾȜ†áŚáÜŚąÜśēį
1.ś†áŚáÜŚąÜśēįŚŹĮšĽ•ÁĽôŚáļśēįŚÄľŤ∑ĚÁ¶ĽŚĚáŚÄľÁöĄÁõłŚĮĻšĹćÁĹģԾƍģ°ÁģóśĖĻś≥ēśėĮÁĒ®śēįŚÄľŚáŹŚéĽŚĚáŚÄľśČÄŚĺóÁöĄŚ∑ģťô§šĽ•ś†áŚáÜŚ∑ģ„Äā
2.śēįśćģśú暼éŚĮĻÁßįÁöĄťíüŚĹĘŚąÜŚłÉśó∂ÔľĆÁĽŹť™Ćś≥ēŚąôŤ°®śėéÔľö
Ôľą1ÔľČÁļ¶śúČ68%ÁöĄśēįśćģšłéŚĻ≥ŚĚáśēįÁöĄŤ∑ĚÁ¶ĽŚú®1šł™ś†áŚáÜŚ∑ģšĻčŚÜÖÔľõ
Ôľą2ÔľČÁļ¶śúČ95%ÁöĄśēįśćģšłéŚĻ≥ŚĚáśēįÁöĄŤ∑ĚÁ¶ĽŚú®2šł™ś†áŚáÜŚ∑ģšĻčŚÜÖÔľõ
Ôľą3ÔľČÁļ¶śúČ99%ÁöĄśēįśćģšłéŚĻ≥ŚĚáśēįÁöĄŤ∑ĚÁ¶ĽŚú®3šł™ś†áŚáÜŚ∑ģšĻčŚÜÖ„Äā
3.ŚĮĻšļéśú暼éŚĮĻÁßįÁöĄťíüŚĹĘŚąÜŚłÉÁöĄś†áŚáÜŚąÜśēįÔľö
Ôľą1ÔľČÁļ¶śúČ68%ÁöĄś†áŚáÜŚąÜśēįŚú®[-1ÔľĆ+1]ŤĆÉŚõīŚÜÖÔľõ
Ôľą2ÔľČÁļ¶śúČ95%ÁöĄś†áŚáÜŚąÜśēįŚú®[-2ÔľĆ+2]ŤĆÉŚõīšĻčŚÜÖÔľõ
Ôľą3ÔľČÁļ¶śúČ99%ÁöĄś†áŚáÜŚąÜśēįŚú®[-3ÔľĆ+3]ŤĆÉŚõīšĻčŚÜÖ„Äā
1„ÄĀPearsonÁõłŚÖ≥Á≥ĽśēįÁöĄŚŹĖŚÄľŤĆÉŚõīŚú®+1ŚíĆ-1šĻčťóīԾƌć≥-1‚ȧr‚ȧ1„Äā
Ôľą1Ծȍč•0<r‚ȧ1Ծƍ°®śė錏ėťáŹXŚíĆYšĻčťóīŚ≠ėŚú®ś≠£ÁļŅśÄßÁõłŚÖ≥ŚÖ≥Á≥ĽÔľõ
Ôľą2Ծȍč•-1‚ȧr<0Ծƍ°®śė錏ėťáŹXŚíĆYšĻčťóīŚ≠ėŚú®ŤīüÁļŅśÄßÁõłŚÖ≥ŚÖ≥Á≥ĽÔľõ
Ôľą3Ծȍč•r=1Ծƍ°®śė錏ėťáŹXŚíĆYšĻčťóīšłļŚģĆŚÖ®ś≠£ÁļŅśÄßÁõłŚÖ≥Ôľõ
Ôľą4Ծȍč•r=-1Ծƍ°®śė錏ėťáŹXŚíĆYšĻčťóīšłļŚģĆŚÖ®ŤīüÁļŅśÄßÁõłŚÖ≥Ôľõ
Ôľą5ԾȌĹď|r|=1śó∂ԾƌŹėťáŹYÁöĄŚŹĖŚÄľŚģĆŚÖ®šĺĚŤĶĖšļéXÔľõ
Ôľą6ԾȌĹďr=0śó∂ԾƍĮīśėéYŚíĆXšĻčťóīšłćŚ≠ėŚú®ÁļŅśÄßÁõłŚÖ≥ŚÖ≥Á≥Ľ„Äā
2„ÄĀś†ĻśćģŚģěťôÖśēįśćģŤģ°ÁģóŚáļÁöĄrԾƌÖ∂ŚŹĖŚÄľŤĆÉŚõīšłÄŤą¨šłļ-1<r<1„Äā
Śú®ŤĮīśėéšł§šł™ŚŹėťáŹšĻčťóīÁöĄÁļŅśÄߌÖ≥Á≥ĽÁöĄŚľļŚľĪśó∂ԾƜ†ĻśćģÁĽŹť™ĆŚŹĮÁõłŚÖ≥Á®čŚļ¶ŚąÜšłļšĽ•šłčŚá†ÁßćśÉÖŚÜĶ:
(1)ŚĹď|r[‚Č•0.8śó∂ԾƌŹĮŤßÜšłļťęėŚļ¶ÁõłŚÖ≥;
(2)ŚĹď0.5‚ȧ|r|<0.8śó∂ԾƌŹĮŤßÜšłļšł≠Śļ¶ÁõłŚÖ≥;
(3ԾȌĹď0.3‚ȧ|r|<0.5śó∂ԾƌŹĮŤßÜšłļšĹéŚļ¶ÁõłŚÖ≥;
(4)ŚĹď|r|<0.3śó∂ԾƍĮīśėéšł§šł™ŚŹėťáŹšĻčťóīÁöĄÁõłŚÖ≥Á®čŚļ¶śěĀŚľĪŚŹĮŤßÜšłļśó†ÁļŅśÄßÁõłŚÖ≥ŚÖ≥Á≥Ľ„Äā
Śüļśú¨śĖĻś≥ē | ťÄāÁĒ®śĚ°šĽ∂ |
ÁģÄŚćēťöŹśúļśäĹś†∑ | ŤŅôÁßćśäĹś†∑śĖĻś≥ēÁöĄťÄāÁĒ®śĚ°šĽ∂śėĮ:‚φśäĹś†∑ś°Üšł≠ś≤°śúČśõīŚ§öŚŹĮšĽ•Śą©ÁĒ®ÁöĄŤĺÖŚä©šŅ°śĀĮ;‚Ď°ŤįÉśü•ŚĮĻŤĪ°ŚąÜŚłÉÁöĄŤĆÉŚõīšłćŚĻŅťėĒ;‚ĎĘšł™šĹďšĻčťóīÁöĄŚ∑ģŚľāšłćśėĮŚĺąŚ§ß„Äā |
ŚąÜŚĪāśäĹś†∑ | ŚąÜŚĪāśäĹś†∑ÁöĄŚļĒÁĒ®śĚ°šĽ∂śėĮ:śäĹś†∑ś°Üšł≠śúČŤ∂≥Ś§üÁöĄŤĺÖŚä©šŅ°śĀĮ,ŤÉĹŚ§üŚįܜļšĹďŚćēšĹćśĆČśüźÁß朆áŚáÜŚąíŚąÜŚąįŚźĄŚĪāšĻčšł≠,ŚģěÁéįŚú®ŚźĆšłÄŚĪāŚÜÖŚźĄŚćēšĹćšĻčťóīÁöĄŚ∑ģŚľāŚįĹŚŹĮŤÉĹŚúįŚįŹ,šłćŚźĆŚĪāšĻčťóīŚźĄŚćēšĹćÁöĄŚ∑ģŚľāŚįĹŚŹĮŤÉĹŚúįŚ§ß„Äā |
Á≥ĽÁĽüśäĹś†∑ | - |
ŚąÜťė∂śģĶśäĹś†∑ | Śú®Ś§ßŤĆÉŚõīÁöĄśäĹś†∑ŤįÉśü•šł≠,ťááÁĒ®Ś§öťė∂śģĶśäĹś†∑śėĮŚŅÖŤ¶ĀÁöĄ„Äā |
śēīÁ姜äĹś†∑ | ŚļĒÁĒ®śēīÁ姜äĹś†∑śó∂Ծƍ¶ĀśĪāŚźĄÁ姜úČŤĺÉŚ•ĹÁöĄšĽ£Ť°®śÄßԾƌć≥Á姌ÜÖŚźĄŚćēšĹćÁöĄŚ∑ģŚľāŤ¶ĀŚ§ßÔľĆÁ姝óīŚ∑ģŚľāŤ¶ĀŚįŹÔľõśēīÁ姜äĹś†∑ÁČĻŚąęťÄāŚźąšļéŚĮĻśüźšļõÁČĻśģäÁĺ§ÁĽďśěĄŤŅõŤ°ĆŤįÉśü•„Äā |
1.ŚŹ™ś∂ČŚŹäšłÄšł™Ťá™ŚŹėťáŹÁöĄšłÄŚÖÉÁļŅśÄߌõěŚĹíś®°Śě茏ĮšĽ•Ť°®Á§ļšłļÔľö
„ÄÄ„ÄÄY=ő≤0+ő≤1X+őĶ
ŚľŹšł≠Ôľöő≤0ŚíĆő≤1šłļś®°ŚěčÁöĄŚŹāśēį„Äā
Ôľą1ÔľČYśėĮXÁöĄÁļŅśÄߌáĹśēįÔľąő≤0+ő≤1XԾȌ䆚łäŤĮĮŚ∑ģť°ĻőĶ„Äā
Ôľą2ÔľČő≤0+ő≤1XŚŹćśė†šļÜÁĒĪšļéXÁöĄŚŹėŚĆĖŤÄĆŚľēŤĶ∑ÁöĄYÁöĄÁļŅśÄߌŹėŚĆĖ„Äā
Ôľą3ԾȍĮĮŚ∑ģť°ĻőĶśėĮšł™ťöŹśúļŚŹėťáŹÔľĆŚŹćśė†šļÜťô§XŚíĆYšĻčťóīÁöĄÁļŅśÄߌÖ≥Á≥ĽšĻ茧ĖÁöĄťöŹśúļŚõ†Áī†ŚĮĻYÁöĄŚĹĪŚďćԾƜėĮšłćŤÉĹÁĒĪXŚíĆYšĻčťóīÁöĄÁļŅśÄߌÖ≥Á≥ĽśČÄŤß£ťáäÁöĄYÁöĄŚŹėŚľāśÄß„Äā
2.śŹŹŤŅįŚõ†ŚŹėťáŹYÁöĄśúüśúõEÔľąYԾȌ¶āšĹēšĺĚŤĶĖŤá™ŚŹėťáŹXÁöĄśĖĻÁ®čÁßįšłļŚõěŚĹíśĖĻÁ®č„Äā
Ôľą1ԾȚłÄŚÖÉÁļŅśÄߌõěŚĹíśĖĻÁ®čÁöĄŚĹĘŚľŹšłļÔľö
„ÄÄ„ÄÄ EÔľąYÔľČ=ő≤0+ő≤1X
Ôľą2ԾȚłÄŚÖÉÁļŅśÄߌõěŚĹíśĖĻÁ®čÁöĄŚõĺÁ§ļśėĮšłÄśĚ°ÁõīÁļŅÔľĆő≤0śėĮŚõěŚĹíÁõīÁļŅÁöĄśą™Ť∑ĚÔľĆő≤1śėĮŚõěŚĹíÁõīÁļŅÁöĄśĖúÁéáԾƍ°®Á§ļXśĮŹŚŹėŚä®šłÄšł™ŚćēšĹćśó∂ÔľĆEÔľąYÔľČÁöĄŚŹėŚä®ťáŹ„Äā
1.ŚÜ≥ŚģöÁ≥ĽśēįR2ԾƚĻüÁßįšłļśčüŚźąšľėŚļ¶śąĖŚą§ŚģöÁ≥ĽśēįԾƌŹĮšĽ•śĶčŚļ¶ŚõěŚĹíś®°ŚěčŚĮĻś†∑śú¨śēįśćģÁöĄśčüŚźąÁ®čŚļ¶„Äā
2.ŚÜ≥ŚģöÁ≥ĽśēįśėĮŚõěŚĹíś®°ŚěčśČÄŤÉĹŤß£ťáäÁöĄŚõ†ŚŹėťáŹŚŹėŚĆĖŚć†Śõ†ŚŹėťáŹśÄĽŚŹėŚĆĖÁöĄśĮĒšĺčԾƌŹĖŚÄľŤĆÉŚõīŚú®0Śąį1šĻčťóī„Äā
Ôľą1ԾȌÜ≥ŚģöÁ≥ĽśēįŤ∂äťęėԾƜ®°ŚěčÁöĄśčüŚźąśēąśěúŚįĪŤ∂䌕ĹԾƌć≥ś®°ŚěčŤß£ťáäŚõ†ŚŹėťáŹÁöĄŤÉĹŚäõŤ∂䌾ļ„Äā
Ôľą2ԾȌ¶āśěúśČÄśúČŤßāśĶčÁāĻťÉĹŤźĹŚú®ŚõěŚĹíÁõīÁļŅšłäÔľĆR2=1ԾƍĮīśėéŚõěŚĹíÁõīÁļŅŚŹĮšĽ•Ťß£ťáäŚõ†ŚŹėťáŹÁöĄśČÄśúČŚŹėŚĆĖ„Äā
Ôľą3ÔľČR2=0ԾƍĮīśėéŚõěŚĹíÁõīÁļŅśó†ś≥ēŤß£ťáäŚõ†ŚŹėťáŹÁöĄŚŹėŚĆĖԾƌõ†ŚŹėťáŹÁöĄŚŹėŚĆĖšłéŤá™ŚŹėťáŹśó†ŚÖ≥„Äā
Ôľą4ÔľČÁéįŚģěŚļĒÁĒ®šł≠R2Ś§ßŚ§öŤźĹŚú®0ŚíĆ1šĻčťóīÔľĆR2Ť∂äśé•ŤŅĎšļé1ԾƌõěŚĹíś®°ŚěčÁöĄśčüŚźąśēąśěúŤ∂䌕ĹÔľõR2Ť∂äśé•ŤŅĎšļé0ԾƌõěŚĹíś®°ŚěčÁöĄśčüŚźąśēąśěúŤ∂äŚ∑ģ„Äā
ÔľąšłÄÔľČÁĽĚŚĮĻśēįśó∂ťóīŚļŹŚąóŚļŹśó∂ŚĻ≥ŚĚáśēįÁöĄŤģ°Áģó
śó∂śúüŚļŹŚąó | ÁģÄŚćēÁģóśúĮŚĻ≥ŚĚá | ||
śó∂ÁāĻ ŚļŹŚąó | ŤŅěÁĽ≠śó∂ÁāĻ ÔľąšĽ•Ś§©šłļśó∂ťóīŚćēšĹćÔľČ | ťÄźśó•ÁôĽŤģįťÄźśó•śé팹ó | ÁģÄŚćēÁģóśúĮŚĻ≥ŚĚá |
śĆᜆáŚÄľŚŹėŚä®śó∂śČćÁôĽŤģį | Śä†śĚÉÁģóśúĮŚĻ≥ŚĚá | ||
ťóīśĖ≠śó∂ÁāĻ | ťóīťöĒśó∂ťóīÁõłÁ≠Č | šł§ś¨°ŚĻ≥ŚĚáÔľöŚĚášłļÁģÄŚćēÁģóśúĮŚĻ≥ŚĚá | |
ťóīťöĒśó∂ťóīšłćÁõłÁ≠Č | šł§ś¨°ŚĻ≥ŚĚáÔľö Á¨¨šłÄś¨°ÁģÄŚćēÁģóśúĮŚĻ≥ŚĚá Á¨¨šļĆś¨°Śä†śĚÉÁģóśúĮŚĻ≥ŚĚá | ||
ÔľąšļĆÔľČÁõłŚĮĻśēįśąĖŚĻ≥ŚĚáśēįśó∂ťóīŚļŹŚąóŚļŹśó∂ŚĻ≥ŚĚáśēį
Ťģ°ÁģóśÄĚŤ∑ĮÔľö
Ôľą1ԾȌąÜŚąęśĪāŚáļŚąÜŚ≠źśĆᜆáŚíĆŚąÜśĮćśĆᜆáśó∂ťóīŚļŹŚąóÁöĄŚļŹśó∂ŚĻ≥ŚĚáśēįÔľĆÁĄ∂ŚźéŚÜćŤŅõŤ°ĆŚĮĻśĮĒ„Äā
Ôľą2ԾȌąÜŚ≠źśĆᜆáŚíĆŚąÜśĮćśĆᜆáśó∂ťóīŚļŹŚąóÁöĄŚļŹśó∂ŚĻ≥ŚĚáśēįԾƌŹāÁÖßÁĽĚŚĮĻśēįśó∂ťóīŚļŹŚąóŚļŹśó∂ŚĻ≥ŚĚáśēįÁöĄŤģ°Áģó„Äā
ÔľąšłÄԾȌĘěťēŅťáŹÔľĚśä•ŚĎäśúüśįīŚĻ≥-ŚüļśúüśįīŚĻ≥
1.ťÄźśúüŚĘěťēŅťáŹÔľöśä•ŚĎäśúüśįīŚĻ≥šłéŚČ暳ĜúüśįīŚĻ≥šĻčŚ∑ģ„ÄāŤģ°ÁģóŚÖ¨ŚľŹšłļÔľö‚ąÜi=yi-yi-1
2.ÁīĮŤģ°ŚĘěťēŅťáŹÔľöśä•ŚĎäśúüśįīŚĻ≥šłéśüźšłÄŚõļŚģöśó∂śúüśįīŚĻ≥ÔľąťÄöŚłłśėĮśó∂ťóīŚļŹŚąóśúÄŚąĚśįīŚĻ≥ԾȚĻčŚ∑ģ„Äā
ÔľąšļĆԾȌĻ≥ŚĚáŚĘěťēŅťáŹ

ÔľąšłÄԾȌŹĎŚĪēťÄüŚļ¶
1„ÄĀŚŹĎŚĪēťÄüŚļ¶=śä•ŚĎäśúüśįīŚĻ≥/ŚüļśúüśįīŚĻ≥
ŚģöŚüļŚŹĎŚĪēťÄüŚļ¶=śä•ŚĎäśúüśįīŚĻ≥/śüźšłÄŚõļŚģöśó∂śúüśįīŚĻ≥
ÁéĮśĮĒŚŹĎŚĪēťÄüŚļ¶=śä•ŚĎäśúüśįīŚĻ≥/ŚČ暳Ĝó∂śúüśįīŚĻ≥
2.ŚģöŚüļŚŹĎŚĪēťÄüŚļ¶šłéÁéĮśĮĒŚŹĎŚĪēťÄüŚļ¶šĻčťóīÁöĄŚÖ≥Á≥Ľ
‚φŚģöŚüļŚŹĎŚĪēťÄüŚļ¶Á≠ČšļéÁõłŚļĒśó∂śúüŚÜÖŚźĄÁéĮśĮĒŚŹĎŚĪēťÄüŚļ¶ÁöĄŤŅěšĻėÁßĮ„Äā
‚Ď°šł§šł™ÁõłťāĽśó∂śúüŚģöŚüļŚŹĎŚĪēťÄüŚļ¶ÁöĄśĮĒÁéáÁ≠ČšļéÁõłŚļĒśó∂śúüÁöĄÁéĮśĮĒŚŹĎŚĪēťÄüŚļ¶„Äā
ÔľąšļĆԾȌĘěťēŅťÄüŚļ¶

„ÄźśŹźÁ§ļ„ÄĎÁéĮśĮĒŚĘěťēŅťÄüŚļ¶=ÁéĮśĮĒŚŹĎŚĪēťÄüŚļ¶-1„Äā
3.ŚģöŚüļŚĘěťēŅťÄüŚļ¶šłéÁéĮśĮĒŚĘěťēŅťÄüŚļ¶šłćŤÉĹŚÉŹŚģöŚüļŚŹĎŚĪēťÄüŚļ¶šłéÁéĮśĮĒŚŹĎŚĪēťÄüŚļ¶ťā£ś†∑šļíÁõłśé®Áģó„Äā
4.ŚģöŚüļŚĘěťēŅťÄüŚļ¶šłéÁéĮśĮĒŚĘěťēŅťÄüŚļ¶šĻčťóīÁöĄśé®ÁģóԾƌŅÖť°ĽťÄöŤŅáŚģöŚüļŚŹĎŚĪēťÄüŚļ¶šłéÁéĮśĮĒŚŹĎŚĪēťÄüŚļ¶śČćŤÉĹŤŅõŤ°Ć„Äā
ÔľąšłÄԾȌĻ≥ŚĚጏόĪēťÄüŚļ¶‚ÄĒ‚ÄĒťááÁĒ®Śá†šĹēŚĻ≥ŚĚáś≥ē„Äā
ÔľąšļĆԾȌĻ≥ŚĚáŚĘěťēŅťÄüŚļ¶
1.ŚĻ≥ŚĚáŚĘěťēŅťÄüŚļ¶śóĘšłćŤÉĹÁĒĪŚźĄśúüÁöĄÁéĮśĮĒŚĘěťēŅťÄüŚļ¶śĪāŚĺóԾƚĻüšłćŤÉĹś†ĻśćģšłÄŚģöśó∂śúüÁöĄśÄĽŚĘěťēŅťÄüŚļ¶Ťģ°Áģó„Äā
2.Ťģ°ÁģóśÄĚŤ∑Į
Ôľą1ԾȌĻ≥ŚĚáŚĘěťēŅťÄüŚļ¶śėĮťÄöŤŅáŚģÉšłéŚĻ≥ŚĚጏόĪēťÄüŚļ¶šĻčťóīÁöĄśēįťáŹŚÖ≥Á≥ĽśĪāŚĺóÁöĄ„Äā
Ôľą2ԾȌĻ≥ŚĚáŚĘěťēŅťÄüŚļ¶ÔľĚŚĻ≥ŚĚጏόĪēťÄüŚļ¶Ôľć1„Äā
1.‚ÄúŚĘěťēŅ1%ÁöĄÁĽĚŚĮĻŚÄľ‚ÄĚśėĮŤŅõŤ°ĆŤŅôšłÄŚąÜśěźÁöĄśĆᜆá„ÄāŚģÉŚŹćśė†ŚźĆś†∑ÁöĄŚĘěťēŅťÄüŚļ¶ÔľĆŚú®šłćŚźĆśó∂ťóīśĚ°šĽ∂šłčśČÄŚĆÖŚźęÁöĄÁĽĚŚĮĻśįīŚĻ≥„Äā
2.Ťģ°ÁģóŚÖ¨ŚľŹ

śÉ≥Ť¶ĀšłčŤĹĹśú¨śĖáŚÜÖŚģĻÁöĄŚźĆŚ≠¶ÔľĆÁāĻŚáĽšłčŤĹĹśĆČťíģԾƌć≥ŚŹĮŚÖćŤīĻšłčŤĹĹPDFÁČąśú¨„Äā
šłčŤĹĹŚįŹśēôÁ®čÔľö
‚φśČčśúļÁęĮšłčŤĹĹÔľöÁāĻŚáĽŚŹ≥šĺßšłčŤĹĹśĆČťíģŚć≥ŚŹĮšłčŤĹĹԾƌ¶āŚõĺÁ§ļśČÄŚú®šĹćÁĹģÔľö

‚Ď°ÁĒĶŤĄĎÁęĮšłčŤĹĹÔľöÁāĻŚáĽŚ∑¶šĺßšłčŤĹĹśĆČťíģŚć≥ŚŹĮšłčŤĹĹԾƌ¶āŚõĺÁ§ļśČÄŚú®šĹćÁĹģÔľö

śł©ť¶®śŹźÁ§ļÔľöśĖáÁę†ÁĒĪšĹúŤÄÖ233ÁĹĎś†°-oyjlÁč¨Áę茹õšĹúŚģĆśąźÔľĆśú™ÁĽŹŤĎóšĹúśĚÉšļļŚźĆśĄŹÁ¶Āś≠ʍŨŤĹĹ„Äā

